In a world where data is growing at an unprecedented rate, traditional data processing tools often struggle to keep up. This is where PySpark steps in. Built on the robust Apache Spark engine, PySpark brings the power of distributed computing to Python, allowing you to process large datasets quickly and efficiently.
Whether you're a data scientist processing massive amounts of data or a developer creating scalable data applications, PySpark provides the speed, flexibility, and ease of use necessary to meet today's data challenges. In this article, we'll learn about what PySpark is and why it's gaining popularity as a big data processing tool.
Understanding PySpark
PySpark is the Python API for Apache Spark, an open-source, distributed computing system designed for processing large datasets. Apache Spark itself is a fast, in-memory data processing engine that allows you to scale your computations efficiently across a cluster of computers. PySpark allows Python developers to use Spark's capabilities, making it easier to work with big data using Python code.
The fundamental benefit of Spark over old data processing techniques, such as Hadoop, is its ability to process much faster. Instead of writing the data to the disk, Spark processes it in memory, thereby being much faster. PySpark brings this with the ease of Python, which is a very attractive feature for data scientists, analysts, and developers with Python knowledge.
PySpark is supported by the most prominent programming languages, such as Java, Scala, R, and Python. However, it is most used by Python users due to its strong support of libraries like Pandas, NumPy, and Matplotlib. It enables you to leverage the huge universe of Python libraries coupled with the scalability and high speeds offered by Spark.
Features of PySpark
One of the main reasons for using PySpark is its capacity to process large-scale data in a distributed fashion. This implies that it can scale from one machine to thousands of machines without compromising on speed. PySpark supports both batch and real-time data, so it is flexible enough to be used for a variety of data processing activities.
DataFrame and SQL support: PySpark allows working with DataFrames, similar to relational tables, and enables SQL queries through Spark SQL for efficient data manipulation and powerful querying capabilities.
Machine learning: PySpark integrates with MLlib, offering classification, regression, clustering, and collaborative filtering algorithms to build sophisticated machine learning models on large datasets.

Why Should You Use PySpark?
If you’re working with large datasets, PySpark can be a game-changer. The following are some of the top reasons why you should consider using PySpark for your data processing and analysis tasks:
Speed and Performance:
PySpark excels in speed due to in-memory data processing, reducing the time needed for computations. Unlike disk-based systems, it avoids reading and writing to disk, making it ideal for applications like real-time analytics and machine learning. PySpark also distributes tasks across a cluster, ensuring fast processing even with massive datasets and maintaining consistent performance, whether on a single machine or large clusters.
Scalability for Big Data:
PySpark scales efficiently, processing massive datasets with ease. It leverages Spark’s distributed computing to handle large data volumes, whether on a local machine or a vast cluster. Industries dealing with big data, like e-commerce and healthcare, use PySpark for real-time analysis and predictive modeling. This scalability ensures PySpark remains a reliable choice for processing large amounts of structured or unstructured data.
Simplified Data Processing:
PySpark simplifies complex data processing tasks by abstracting distributed computing complexities. Python users can work with large datasets seamlessly, using DataFrames as they would with smaller datasets. PySpark also integrates effortlessly with Python libraries like Pandas, NumPy, and TensorFlow, making it a comprehensive tool for data manipulation, visualization, and machine learning. This integration enables developers to tackle big data without leaving the Python environment.
Real-Time Data Processing:
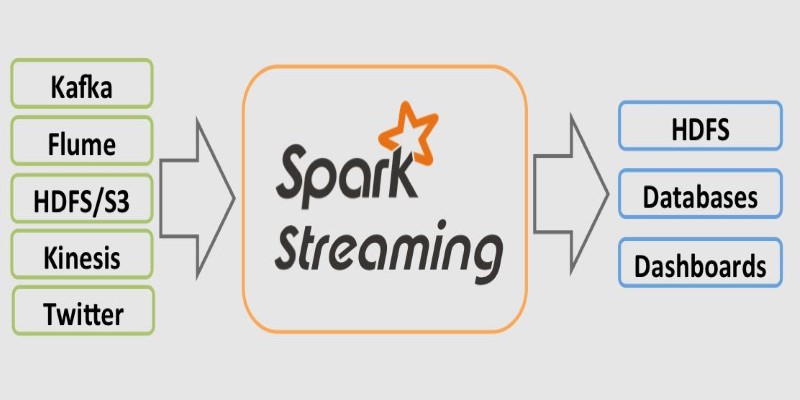
PySpark supports real-time data processing through Spark Streaming, enabling you to analyze live data streams, such as social media or sensor data. Real-time analytics is crucial for applications that require immediate insights, like fraud detection and website traffic analysis. PySpark's ability to handle both batch and streaming data ensures seamless integration of real-time and historical data, delivering timely and accurate results for dynamic applications.
Strong Ecosystem and Community Support:
PySpark benefits from a large ecosystem of libraries and an active community of users. The availability of resources, tutorials, and documentation makes learning and troubleshooting easier. The community consistently contributes improvements and new features, ensuring PySpark evolves with the latest advancements in data processing. This robust support network enhances PySpark’s usability, making it accessible and adaptable for developers working on diverse data projects.
Integration with Other Big Data Tools:
PySpark integrates seamlessly with other big data tools like Hadoop and Hive. It can read and write data from the Hadoop Distributed File System (HDFS), making it a perfect fit for organizations already using Hadoop. PySpark’s compatibility with machine learning frameworks like TensorFlow and Scikit-Learn further expands its flexibility, allowing developers to create end-to-end data processing and machine learning pipelines in a unified ecosystem.
Conclusion
PySpark is a powerful tool for processing large datasets efficiently, offering speed, scalability, and ease of use. Its integration with Python makes it accessible to developers and data scientists. In contrast, its ability to handle both batch and real-time data sets it apart from traditional data processing tools. With a strong ecosystem, community support, and seamless integration with other big data tools, PySpark is an essential resource for anyone looking to work with big data and machine learning applications.