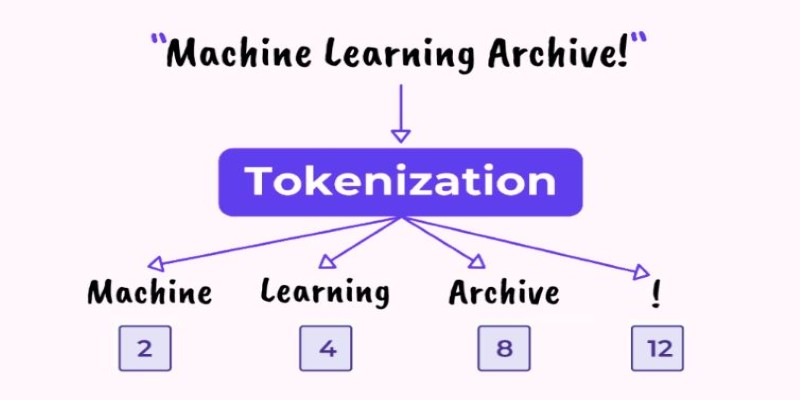
Tokenization is a fundamental process in Natural Language Processing (NLP) that breaks down language into manageable parts, allowing machines to understand and process text. Whether it's for chatbots, translation models, or search engines, tokenization helps structure raw text for analysis. By dividing text into smaller units like words or subwords, tokenization enables machines to perform tasks like grammar analysis and sentiment detection.
Despite being a fundamental idea, tokenization's contribution to NLP is extremely important in helping computers handle human language. Knowing tokenization is central to comprehending the text processing and analysis capabilities of NLP systems.
Understanding Tokenization in NLP
Tokenization is similar to teaching a computer to read by dividing text into bite-sized chunks. When we read, we naturally understand words and how they relate to each other, but to machines, raw text is merely a flow of characters. Tokenization fills this gap by cutting text into meaningful chunks—words, subwords, sentences, or even single characters—so that a computer can work with them efficiently.
Imagine you have the sentence:
"The cat sat on the mat."
A basic word tokenizer would break it down into:
["The", "cat", "sat", "on", "the", "mat", "."]
Each word becomes a separate unit, making it easier for an NLP model to analyze and interpret the sentence. But things aren't always so simple. Take the phrase "Let's go!"—should it be split as ["Let", "'s", "go", "!"], or should "Let's" stay intact? The choice matters because contractions, possessives, and abbreviations influence how a model understands language.
It becomes even more challenging for languages such as Chinese or Japanese, in which words are not separated by space. Tokenization in these instances depends on sophisticated algorithms to pinpoint logical word separations. Even more inflected languages, such as German or Turkish, form long compounding words with which old-school tokenizers might have trouble dealing.
At its core, tokenization is the first step in helping machines make sense of human language, shaping how they read, interpret, and respond.
Different Types of Tokenization
Tokenization varies depending on the granularity required for processing. The three most common approaches include word tokenization, subword tokenization, and sentence tokenization.
Word Tokenization
Word tokenization is the most intuitive approach. It splits a sentence into individual words, using spaces or punctuation as natural delimiters. While this works well for many cases, it struggles with compound words, contractions, and domain-specific jargon. Consider a medical text—should “heart rate” be split into separate tokens, or should it be treated as a single entity? The decision depends on the application and the level of semantic understanding required.
Subword Tokenization
Subword tokenization is a more refined approach, often used in modern NLP models like BERT and GPT. Instead of splitting text into whole words, it breaks words into meaningful sub-units. This is particularly useful for handling rare words, misspellings, and morphological variations. Techniques such as Byte Pair Encoding (BPE) and WordPiece tokenization create token sets that include both whole words and subwords. For example, the word “unhappiness” might be split into ["un", "happiness"], preserving meaning while reducing the need for a massive vocabulary.
Sentence Tokenization
Sentence tokenization, also called sentence segmentation, focuses on dividing large text blocks into individual sentences. This helps in applications like summarization, machine translation, and text generation. While a simple rule-based approach might use punctuation like periods or question marks to define sentence boundaries, real-world text isn’t always that clean. Abbreviations (e.g., Dr., Inc.) or missing punctuation in informal text can complicate segmentation, requiring more sophisticated models to determine where one thought ends and another begins.
The Role of Tokenization in NLP Models
Tokenization is the foundational step in nearly all NLP tasks, enabling machines to understand and process human language. Whether used for search engines, chatbots, or sentiment analysis, tokenization structures text into manageable units that models can analyze.

In machine translation, accurate tokenization ensures that words are properly recognized, preventing misinterpretations that could distort the translation. For sentiment analysis, tokenization helps capture emotions accurately. For example, the phrase "This is not bad" could be misclassified if tokenization fails to understand the nuanced meaning.
Modern language models, like ChatGPT, BERT, and LLaMA, rely on tokenization to process language efficiently. These models transform text into tokens, which are then turned into mathematical representations. This allows the model to understand context and different writing styles and even predict the next word in a sequence.
Tokenization also plays a key role in text generation, affecting the fluency and coherence of AI responses. Poor tokenization can result in awkward phrasing, while effective tokenization helps create more natural and human-like outputs, improving the quality of the generated text.
Challenges in Tokenization
Despite its importance, tokenization faces several challenges. One of the biggest hurdles is handling ambiguities. Words like "lead" can have multiple meanings depending on context, and a simple tokenizer can't distinguish between them without additional context.
Another challenge is language diversity. Tokenization rules that work for English don’t always apply to languages like Chinese, Arabic, or Finnish. For instance, in Chinese, the phrase "北京大学" (Peking University) should remain a single token, but basic tokenization might break it into incorrect segments.
Handling out-of-vocabulary words also poses a problem. Traditional systems replace unknown words with a placeholder token, but modern subword tokenization strategies break words into smaller, recognizable components, helping to process rare or new terms more effectively.
Finally, tokenization efficiency is crucial. NLP models process millions of tokens quickly, and inefficient tokenization can slow down performance, requiring a balance between precision and computational speed.
Conclusion
Tokenization is a vital step in Natural Language Processing, transforming text into manageable units for machine understanding. It plays a key role in various AI applications like search engines, translation, and text generation. Despite its apparent simplicity, tokenization presents challenges like language differences and ambiguity. However, advancements in AI continue to improve tokenization methods, making them more efficient and accurate. As NLP evolves, tokenization will remain essential in enabling machines to understand and process human language effectively.