Neural networks are the backbone of modern AI, powering everything from voice assistants to self-driving cars. But what makes them so effective? The answer lies in activation functions. These tiny mathematical operations decide whether a neuron should "fire" or stay silent, shaping how a network learns and processes data. Without them, neural networks would be nothing more than complex calculators, unable to recognize patterns or make decisions.
Activation functions provide neural networks with their actual power, be it classifying pictures or translating languages. A grasp of activation functions is fundamental to becoming proficient in deep learning and developing models that actually perform in the real world.
What is an Activation Function?
At its core, an activation function is a mathematical formula that controls whether a neural network node (neuron) should be fired or not. When an input is fed into a neuron, the neuron computes it and sends a result. The activation function determines whether the signal from this neuron should be sent to the next layer of the network. It does this by computing the weighted sum of inputs and applying a transformation to this sum to create a final output.
The significance of this change cannot be overemphasized. In the absence of an activation function, the whole network would work like a plain linear model, incapable of dealing with problems demanding advanced decision-making. With the addition of non-linearity through activation functions, neural networks are capable of learning from the data and predicting outcomes based on advanced patterns.
Why Do Neural Networks Need Activation Functions?
Activation functions are important since they mandate non-linearity. Think of trying to plot a straight line given data points on a two-dimensional chart. A linear model is capable only of generating a straight line, and that only serves to narrow its capability of grasping more complex data interdependencies. By incorporating non-linear transformations, however, neural networks are able to map input data into a considerably larger set of possible outputs.
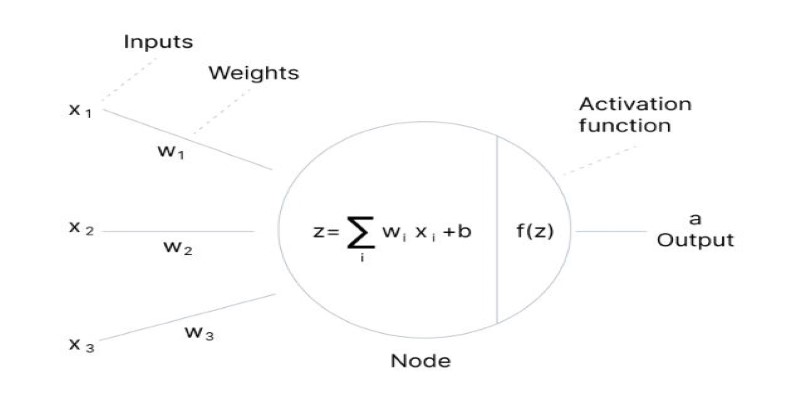
In other words, activation functions provide neural networks with the versatility to learn from high-dimensional, complex data. They enable the model to make adjustments to real-world task intricacies, such as forecasting stock prices, recognizing objects in photographs, or producing human-like language. Without them, neural networks would be considerably less effective and potent.
Another reason activation functions are important is that they enable backpropagation. This is a key algorithm used to train neural networks by adjusting the weights of connections between neurons. During training, the model uses the derivative of the activation function to update weights and improve its performance over time.
Types of Activation Functions
Several types of activation functions are used in neural networks, each with its own advantages and disadvantages. Some are better suited for certain tasks than others. Let's explore the most common ones.
Sigmoid Activation Function
One of the most traditional activation functions is the sigmoid function. It maps input values to a range between 0 and 1, making it particularly useful for binary classification tasks. The formula for the sigmoid function is:
Here, 𝑒 is the natural logarithm base, and 𝑥 is the weighted input sum. It smoothly maps outputs between 0 and 1, making it useful for probability-based tasks. However, it has a drawback—the "vanishing gradient" problem, where gradients shrink for large inputs, slowing or hindering deep network training.
ReLU (Rectified Linear Unit)
The ReLU function has become the most widely used activation function in recent years, especially in deep learning models. It is simple and computationally efficient, with the formula:
ReLU outputs the input if positive; otherwise, it returns zero. It avoids the vanishing gradient issue, enabling faster training. However, it can cause the "dying ReLU" problem, where neurons stop learning due to constant zero outputs. Variants like Leaky ReLU address this by allowing small negative values instead of absolute zero.
Tanh (Hyperbolic Tangent)
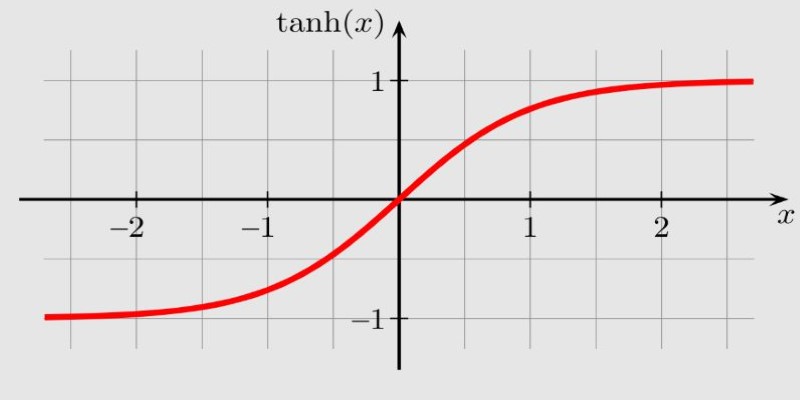
The tanh activation function is similar to the sigmoid but maps the output to a range between -1 and 1 instead of 0 and 1. Its formula is:
Like the sigmoid, tanh suffers from the vanishing gradient problem but tends to perform better in practice because it has a wider output range. It is useful when the output needs to be centered around zero, which helps with learning during training.
Softmax Activation Function
The softmax activation function is primarily used in the output layer of classification problems, particularly when there are multiple classes. It takes a vector of raw scores (logits) and normalizes them into a probability distribution. The formula for softmax is:
Here, represents each element in the input vector, and the denominator is the sum of the exponentials of all elements in the input vector. The softmax function ensures that the output values are probabilities that sum to 1, making it ideal for multi-class classification problems.
Choosing the Right Activation Function
Choosing the right activation function depends on the specific task and model architecture. ReLU is often the default due to its efficiency, but sigmoid works well for binary classification, while softmax is ideal for multi-class problems.
No single activation function is universally best; the choice should align with the network’s goals and data. Experimenting with different functions and analyzing performance is crucial to optimizing neural networks for accuracy, stability, and learning efficiency in deep learning applications.
Conclusion
Activation functions are crucial in neural networks, adding non-linearity to help recognize complex patterns. They are key for tasks like image processing and language understanding. Choosing the right activation function, such as sigmoid, ReLU, or softmax, is vital for optimizing model performance. Since no single function works for every scenario, selecting the appropriate one enhances accuracy and efficiency. A well-chosen activation function ensures that neural networks can tackle intricate problems effectively, improving their ability to deliver precise, reliable results across various applications.











